(este artículo también lo puedes leer en español)
This is Part 1 of the Intellij Love for your (programming) Language series.
You’ve finally managed to write the compiler/engine for your shiny new language. Making sure every thing works (i.e. you respect your language semantics) will get you to the doorstep of your potential users. For them to open the doors of their programming home and let your language in you need another piece of the puzzle: an editor.
Well, at least into my programming home. I do like syntax highlighting and the other goodies that an IDE bring (refactoring, renaming, etc.). If you are like me, then read along.
There are different ways to get a functional editor: Eclipse (via XText or manually), Atom, Notepad++, etc. In this post I will present how I did it for the Jet Brains family of IDEs (IntelliJ, PyCharm, WebStorm, etc.). Why Jet Brains? I like them. I like their dark theme, I like their shortcuts and tools. They do their job pretty darn good, IMHO.
Prerequisites
Jet Brains provide an official tutorial for Custom Language Support. If you have never worked on a custom language for IntelliJ, I suggest that you head there and spent some time understanding the ideas and what is needed. On the remaining I will use names and classes presented there, so having some familiarity will help you understand. I will reference the relative tutorial section while I describe my approach, so feel free to jump back and forth if you need to.
What we will do
You can broadly categorise the editor functions into two types: look n’ feel and functional. In the former I place things like syntax highlighting and folding; the latter relates to refactoring, cross-references, etc. In this post I will only focus in the look n’ feel. This includes:
- Language definition (tutorial – section 2)
- Grammar and Parser (tutorial – section 3)
- Lexer and Parser definition (tutorial – section 4)
- Syntax Highlighter (tutorial – section 5)
- Folding Builder (tutorial – section 12)
More than repeating what the tutorial explains, I will point out the small caveats and help you understand how all things are linked through the IntelliJ PSI and editors API.
I will be using the Epsilon languages as an example as my intention for doing this was to be able to edit Epsilon scripts from within IntelliJ (and friends). In this part I will talk about EOL; Part2 will talk about how support for the other languages was achieved.
The editor code (and other stuff) is hosted in the Kinori Tech repository if you are curious or want to look at the complete code while reading.
Language definition
There is really not much to this part. The only thing that I would add is that if you are providing a group of languages then the “Icons” class (section 2.2) could be for all languages, as opposed as one per language. Also, take some time to create the language icons. I find it really helpful to look at my project tree and quickly see what each file is. Relevant information about icons in Jet Brains is found in these two pages:
- https://plugins.jetbrains.com/docs/intellij/work-with-icons-and-images.html
- https://jetbrains.design/intellij/principles/icons/
Grammar and Parser
My only note is a small change in the Token Type (section 3.1):
public class EolTokenType extends IElementType {
public EolTokenType(@NotNull @NonNls String debugName) {
super(debugName, EolLanguage.INSTANCE);
}
@Override
public String toString() {
return super.toString(); // vs return "SimpleTokenType." + super.toString();
}
}
I found that using “<name>TokenType” as a prefix caused issues when creating error messaged to the user, i.e. the prefix does not add any useful information for the user when showing messages like “exptected COMMA found LEFT_BRACKET”.
The Grammar
How to write a grammar (and later the lexer) requires a separate post. However, if you ave already written a compiler/engine you probably already have a grammar somewhere. Translating your grammar to IntelliJ’s BNF takes time, but is relatively straight forward.
Lexer and Parser definition
The class that needs the most attention is the Parser Definition. The key methods, for me, are getWhitespaceTokens, getCommentTokens and getStringLiteralElements. These three methods tell the editor what tokens are considered white space (usually spaces and line breaks), comments and string literals. Make sure that you return all your supported comments (i.e. single vs multi-line comments).
The Lexer
I had done most of my language developing using XText and Antlr, so having to define the lexer in a separate file was new. I found the JFlex documentation a bit hard to digest, and I could not find really good tutorials out there. Again, the details will probably deserve their own post. I would only say that lexical states are really powerful in JFlex.
Syntax Highlighter
At this point the lexer is creating tokens and the parser is using them to validate the grammar. If you are using the PSI viewer at this point you can see how the CST is built and should be getting any syntax errors reported.
Here is where you make the magic happen!
First you need to group your tokens into “highlight groups”. A common approach is to have separate colors for language constructs (for, then, class, etc.), strings, numbers, comments, constants and operators. Define your own groups and decide what tokens to put into each. We will assign each highlight group a different color and style (bold, italics, etc.). For each highlight group you need a TextAttributesKey and a TextAttributesKey array. I assume the latter means that you can combine multiple styles for each group, but I have not looked into how it works.
The tutorial advocates for the use of static fields for creating your groups:
public static final TextAttributesKey EOL_OPERATORS =
createTextAttributesKey("EOL_OPERATORS", DefaultLanguageHighlighterColors.OPERATION_SIGN);
...
public static final TextAttributesKey[] EOL_OPERATOR_KEYS = new TextAttributesKey[]{EOL_OPERATORS};
Further, they rely on the “DefaultLanguageHighlighterColors” class to assign colors. That class has some of the defaults used by IntelliJ so it is a good starting point. For more personalised styles, you would need to construct your own “TextAttributesKey” objects using your own TextAttributes. Their API seems to favour reuse, at least if you want to keep all definitions in the static domain. But you can create them in your Syntax Highlighter constructor, for example. The TextAttributes class is your friend.
For EOL, I defined 8 groups:
- operators: arithmetic (+, -, /, etc.) and eol specific operators (!, |, ::=, etc.).
- text operators: logical operators (and, or, etc.)
- keywords: for, if, class, operation, etc.
- annotations: @cached, @lazy, etc.
- numbers
- built-in: select, collect, includes, etc.
- string
- comment
The tokens that belong to each group are enforced in the getTokenHighlights method implementation. I used multiple ORs, but perhaps sets or other structure could be better:
package org.eclipse.epislon.labs.intellij.grammar.editor.eol;
import com.intellij.lexer.Lexer;
import com.intellij.openapi.editor.DefaultLanguageHighlighterColors;
import com.intellij.openapi.editor.HighlighterColors;
import com.intellij.openapi.editor.colors.TextAttributesKey;
import com.intellij.openapi.fileTypes.SyntaxHighlighterBase;
import com.intellij.psi.TokenType;
import com.intellij.psi.tree.IElementType;
import org.eclipse.epislon.labs.intellij.grammar.parser.eol.EolLexerAdapter;
import org.eclipse.epislon.labs.intellij.grammar.psi.eol.EolTypes;
import org.jetbrains.annotations.NotNull;
import static com.intellij.openapi.editor.colors.TextAttributesKey.createTextAttributesKey;
public class EolSyntaxHighlighter extends SyntaxHighlighterBase {
public static final TextAttributesKey EOL_OPERATORS =
createTextAttributesKey("EOL_OPERATORS", DefaultLanguageHighlighterColors.OPERATION_SIGN);
public static final TextAttributesKey EOL_TEXT_OPERATORS =
createTextAttributesKey("EOL_TEXT_OPERATORS", DefaultLanguageHighlighterColors.LOCAL_VARIABLE);
public static final TextAttributesKey EOL_KEYWORD =
createTextAttributesKey("EOL_KEYWORD", DefaultLanguageHighlighterColors.INSTANCE_METHOD);
public static final TextAttributesKey EOL_ANNOTATIONS =
createTextAttributesKey("EOL_ANNOTATIONS", DefaultLanguageHighlighterColors.METADATA);
public static final TextAttributesKey EOL_NUMBERS =
createTextAttributesKey("EOL_NUMBERS", DefaultLanguageHighlighterColors.NUMBER);
public static final TextAttributesKey EOL_BUILTIN =
createTextAttributesKey("EOL_BUILTIN", DefaultLanguageHighlighterColors.FUNCTION_CALL);
public static final TextAttributesKey EOL_STRING =
createTextAttributesKey("STRING", DefaultLanguageHighlighterColors.STRING);
public static final TextAttributesKey EOL_COMMENT =
createTextAttributesKey("SIMPLE_COMMENT", DefaultLanguageHighlighterColors.LINE_COMMENT);
public static final TextAttributesKey BAD_CHARACTER =
createTextAttributesKey("SIMPLE_BAD_CHARACTER", HighlighterColors.BAD_CHARACTER);
public static final TextAttributesKey[] EOL_OPERATOR_KEYS = new TextAttributesKey[]{EOL_OPERATORS};
public static final TextAttributesKey[] EOL_TEXT_OPERATOR_KEYS = new TextAttributesKey[]{EOL_TEXT_OPERATORS};
public static final TextAttributesKey[] EOL_KEYWORD_KEYS = new TextAttributesKey[]{EOL_KEYWORD};
public static final TextAttributesKey[] EOL_ANNOTATIONS_KEYS = new TextAttributesKey[]{EOL_ANNOTATIONS};
public static final TextAttributesKey[] EOL_NUMBER_KEYS = new TextAttributesKey[]{EOL_NUMBERS};
public static final TextAttributesKey[] EOL_BUILTIN_KEYS = new TextAttributesKey[]{EOL_BUILTIN};
public static final TextAttributesKey[] EOL_STRING_KEYS = new TextAttributesKey[]{EOL_STRING};
public static final TextAttributesKey[] EOL_COMMENT_KEYS = new TextAttributesKey[]{EOL_COMMENT};
public static final TextAttributesKey[] EMPTY_KEYS = new TextAttributesKey[0];
private static final TextAttributesKey[] BAD_CHAR_KEYS = new TextAttributesKey[]{BAD_CHARACTER};
@NotNull
@Override
public Lexer getHighlightingLexer() {
return new EolLexerAdapter();
}
@NotNull
@Override
public TextAttributesKey[] getTokenHighlights(IElementType tokenType) {
if (tokenType.equals(EolTypes.EOL_ARROW_OP)
|| tokenType.equals(EolTypes.EOL_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_COLON_OP)
|| tokenType.equals(EolTypes.EOL_DIV_ASSIG_OP)
|| tokenType.equals(EolTypes.EOL_DIV_OP)
|| tokenType.equals(EolTypes.EOL_ENUM_OP)
|| tokenType.equals(EolTypes.EOL_EQ_OP)
|| tokenType.equals(EolTypes.EOL_EQUIV_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_GE_OP)
|| tokenType.equals(EolTypes.EOL_GT_OP)
|| tokenType.equals(EolTypes.EOL_IMPLIES_OP)
|| tokenType.equals(EolTypes.EOL_IN_OP)
|| tokenType.equals(EolTypes.EOL_INC_OP)
|| tokenType.equals(EolTypes.EOL_LE_OP)
|| tokenType.equals(EolTypes.EOL_LT_OP)
|| tokenType.equals(EolTypes.EOL_MINUS_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_MODEL_OP)
|| tokenType.equals(EolTypes.EOL_NE_OP)
|| tokenType.equals(EolTypes.EOL_NEG_OP)
|| tokenType.equals(EolTypes.EOL_PLUS_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_PLUS_OP)
|| tokenType.equals(EolTypes.EOL_POINT_OP)
|| tokenType.equals(EolTypes.EOL_POINT_POINT_OP)
|| tokenType.equals(EolTypes.EOL_QUAL_OP)
|| tokenType.equals(EolTypes.EOL_SPECIAL_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_THEN_OP)
|| tokenType.equals(EolTypes.EOL_TIMES_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_TIMES_OP)
) {
return EOL_OPERATOR_KEYS;
}
else if(tokenType.equals(EolTypes.EOL_AND_OP)
|| tokenType.equals(EolTypes.EOL_NOT_OP)
|| tokenType.equals(EolTypes.EOL_OR_OP)
|| tokenType.equals(EolTypes.EOL_XOR_OP)
) {
return EOL_TEXT_OPERATOR_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_ABORT_KEY)
|| tokenType.equals(EolTypes.EOL_BAG_KEY)
|| tokenType.equals(EolTypes.EOL_BREAK_ALL_KEY)
|| tokenType.equals(EolTypes.EOL_BREAK_KEY)
|| tokenType.equals(EolTypes.EOL_CASE_KEY)
|| tokenType.equals(EolTypes.EOL_COL_KEY)
|| tokenType.equals(EolTypes.EOL_CONTINUE_KEY)
|| tokenType.equals(EolTypes.EOL_DEFAULT_KEY)
|| tokenType.equals(EolTypes.EOL_DELETE_KEY)
|| tokenType.equals(EolTypes.EOL_ELSE_KEY)
|| tokenType.equals(EolTypes.EOL_EXT_KEY)
|| tokenType.equals(EolTypes.EOL_FALSE_KEY)
|| tokenType.equals(EolTypes.EOL_FOR_KEY)
|| tokenType.equals(EolTypes.EOL_FUNCTION_KEY)
|| tokenType.equals(EolTypes.EOL_IF_KEY)
|| tokenType.equals(EolTypes.EOL_IMPORT_KEY)
|| tokenType.equals(EolTypes.EOL_IN_KEY)
|| tokenType.equals(EolTypes.EOL_LIST_KEY)
|| tokenType.equals(EolTypes.EOL_MAP_KEY)
|| tokenType.equals(EolTypes.EOL_NATIVE_KEY)
|| tokenType.equals(EolTypes.EOL_NEW_KEY)
|| tokenType.equals(EolTypes.EOL_OPERATION_KEY)
|| tokenType.equals(EolTypes.EOL_ORDSET_KEY)
|| tokenType.equals(EolTypes.EOL_RETURN_KEY)
|| tokenType.equals(EolTypes.EOL_SEQ_KEY)
|| tokenType.equals(EolTypes.EOL_SET_KEY)
|| tokenType.equals(EolTypes.EOL_SWITCH_KEY)
|| tokenType.equals(EolTypes.EOL_THROW_KEY)
|| tokenType.equals(EolTypes.EOL_TRANS_KEY)
|| tokenType.equals(EolTypes.EOL_TRUE_KEY)
|| tokenType.equals(EolTypes.EOL_VAR_KEY)
|| tokenType.equals(EolTypes.EOL_WHILE_KEY)
) {
return EOL_KEYWORD_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_ANNOTATION)
|| tokenType.equals(EolTypes.EOL_EXEC_ANNOT)
|| tokenType.equals(EolTypes.EOL_EXECUTABLE_ANNOTATION)) {
return EOL_ANNOTATIONS_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_FLOAT)) {
return EOL_NUMBER_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_SELF_BIN)
|| tokenType.equals(EolTypes.EOL_LOOP_CNT_BIN)
|| tokenType.equals(EolTypes.EOL_HAS_MORE_BIN)) {
return EOL_BUILTIN_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_STRING)) {
return EOL_STRING_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_BLOCK_COMMENT) || tokenType.equals(EolTypes.EOL_LINE_COMMENT)) {
return EOL_COMMENT_KEYS;
}
else if (tokenType.equals(TokenType.BAD_CHARACTER)) {
return BAD_CHAR_KEYS;
}
else {
return EMPTY_KEYS;
}
}
}
Folding Builder
This took me the longest to figure out. The buildFoldRegions in FoldingBuilder has a bullseye name; basically you need to build folding regions for which ever PSI elements you want. Note that since here we are working with the PSI API, we need to work with the language constructs from our parser, not with tokens. The buildFoldRegions also accepts a quick parameter. Since building the folds for a large file can be time consuming, the quick flag lets you know that you should only build a subset of all the folds.
For EOL I picked two constructs to fold, similar to how Java works on IntelliJ: fold imports and code blocks (i.e. code inside curly braces). If quick, I will only fold imports.
// imports
EpsilonModule module = PsiTreeUtil.findChildOfAnyType(root, false, EpsilonModule.class);
if ((module != null) && !module.getImportStatementList().isEmpty()) {
descriptors.add(new ImportStatementBlockFolding(
module.getNode(),
new TextRange(
module.getImportStatementList().get(0).getTextRange().getStartOffset() + 7,
module.getImportStatementList().get(module.getImportStatementList().size()-1).getTextRange().getEndOffset() + 1))
);
}
The tricky part is getting the text range correct. I start with the first import and then add 7 characters to it’s start offset (line 7). What I accomplish by this is preserve the import keyword (import = 7 characters) so that when folded the user sees: “import …”. The fold ends after the last import’s closing “;” plus 1, so that the semicolon is not visible. For curly braces I used StatementBlocks, which are exactly that, as defined in the EOL grammar:
...
// Statements
statementBlock ::= '{' statement* '}'
...
Here, not offsets used to fold at the braces. It is also possible to change the “place holder text” of the hold. So instead of the three dots (ellipsis?) you can show commas, similes, whatever works for your language. Here is the complete folding builder:
package org.eclipse.epislon.labs.intellij.grammar.language.eol;
import com.intellij.lang.ASTNode;
import com.intellij.lang.folding.*;
import com.intellij.openapi.editor.*;
import com.intellij.openapi.util.TextRange;
import com.intellij.psi.*;
import com.intellij.psi.util.PsiTreeUtil;
import org.eclipse.epislon.labs.intellij.grammar.psi.EpsilonModule;
import org.eclipse.epislon.labs.intellij.grammar.psi.eol.*;
import org.jetbrains.annotations.*;
import java.util.*;
public class EolFoldingBuilder extends FoldingBuilderEx {
public class EolStatementBlockFolding extends FoldingDescriptor {
public EolStatementBlockFolding(@NotNull ASTNode node, @NotNull TextRange range) {
super(node, range);
}
@Nullable
@Override
public String getPlaceholderText() {
return "...";
}
}
public class ImportStatementBlockFolding extends FoldingDescriptor {
public ImportStatementBlockFolding(@NotNull ASTNode node, @NotNull TextRange range) {
super(node, range);
}
@Nullable
@Override
public String getPlaceholderText() {
return "...";
}
}
@NotNull
@Override
public FoldingDescriptor[] buildFoldRegions(@NotNull PsiElement root, @NotNull Document document, boolean quick) {
List<FoldingDescriptor> descriptors = new ArrayList<>();
// imports
EpsilonModule module = PsiTreeUtil.findChildOfAnyType(root, false, EpsilonModule.class);
if ((module != null) && !module.getImportStatementList().isEmpty()) {
descriptors.add(new ImportStatementBlockFolding(
module.getNode(),
new TextRange(module.getImportStatementList().get(0).getTextRange().getStartOffset() + 7,
module.getImportStatementList().get(module.getImportStatementList().size()-1).getTextRange().getEndOffset() + 1))
);
}
if (!quick) {
// all StatementBlocks are collapsible, and since most expressions with a block use a StatementBlock we cover
// most required foldings
for (final EolStatementBlock stmt : PsiTreeUtil.findChildrenOfAnyType(root, false, EolStatementBlock.class)) {
createBlockFoldingDescriptor(descriptors, stmt, stmt.getNode());
}
}
return descriptors.toArray(new FoldingDescriptor[descriptors.size()]);
}
@Nullable
@Override
public String getPlaceholderText(@NotNull ASTNode node) {
return "...";
}
// Only calls for nodes that have a FoldingDescriptor
@Override
public boolean isCollapsedByDefault(@NotNull ASTNode node) {
if (node.getElementType().equals(EolTypes.EOL_MODULE)) {
return true;
}
return false;
}
protected void createBlockFoldingDescriptor(
List<FoldingDescriptor> descriptors,
EolStatementBlock statementBlock,
ASTNode node) {
if (statementBlock != null) {
descriptors.add(new EolStatementBlockFolding(
node,
new TextRange(
statementBlock.getTextRange().getStartOffset() + 1,
statementBlock.getTextRange().getEndOffset() - 1)));
}
}
}
The result
This is a screen shot of the editor in the back, and the editor settings on top.
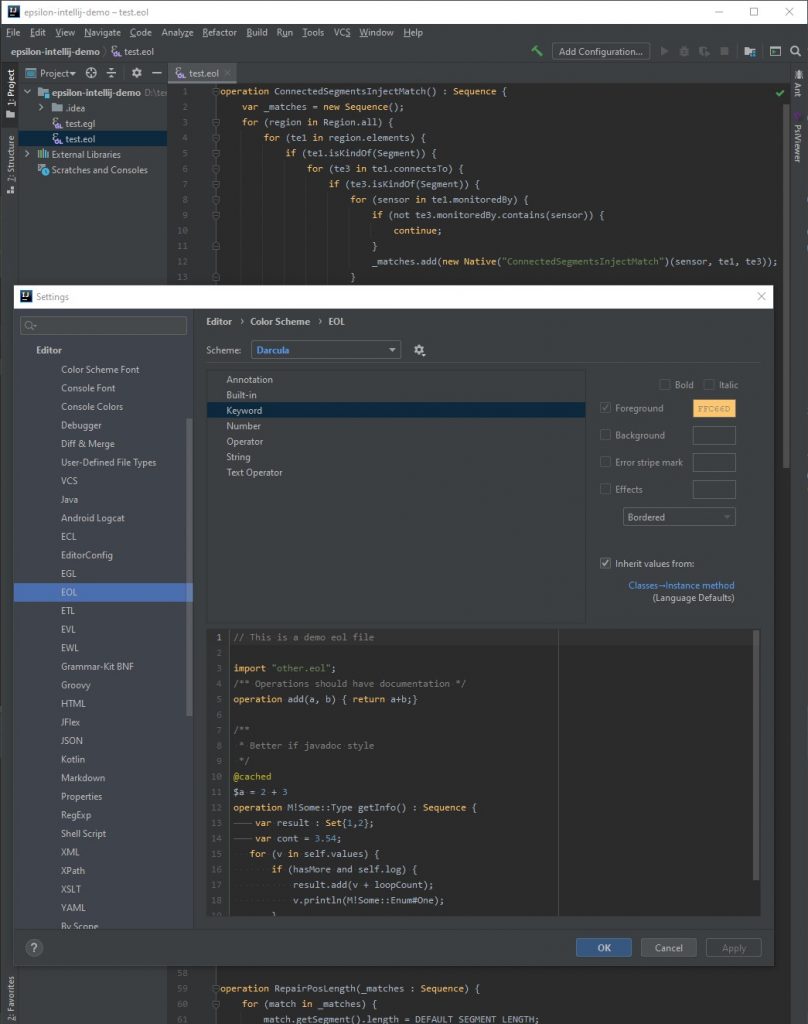
Let me know if you need more information!