(you can also read this post in english)
Esta es la Parte 1 de la serie “Un hogar para tu Lenguaje (de programación) en IntelliJ”.
Por fin lograste escribir el compilador o máquina de ejecución para tu nuevo y reluciente lenguaje. Asegurarse que todo funciona (de acuerdo a la semántica del lenguaje) solo nos lleva hasta la puerta de nuestros usuarios potenciales. Para que te abran las puertas de su entorno de desarrollo y dejen entrar a tu lenguaje se necesita la siguiente pieza del rompecabezas: un editor.
Bueno, al menos en mi entorno de desarrollo. Me gusta ver la sintaxis sobresaltada con diferentes colores y las herramientas que nos proveen los IDEs (integrated development environment, en ingles). Si eres como yo, entonces sigue leyendo.
Hay diferentes maneras de construir un editor para un lenguaje: Eclipse (utilizando XText – o desde cero), Atom, Notepad++, etc. En esta entrada les voy a presentar como se puede hacer para la familia de IDEs de Jet Brains (IngelliJ, PyCharm, WebStorm, etc.). ¿Por qué Jet Brains? Me gustan sus editores. Me gusta su tema oscuro, sus accesos rápidos y las herramientas integradas. La tienen clara, en mi humilde opinión.
Requisitos
Jet Brains tiene un tutorial oficial pata el soporte de lenguajes personalizados. Si nunca has desarrollado un editor para Jet Brains, sugiero leer el tutorial para entender el concepto y lo que se necesita hacer (solo en ingles). En el resto de la entrada voy a utilizar los nombres de clases y términos utilizados allí, así que estar familiarizados con ellos puede ayudar a seguir la entrada. Haré referencia a la sección en particular del tutorial que habla de lo que estoy describiendo, así que puede ser benéfico ir y venir de la página del tutorial.
Lo que vamos a hacer
Podemos categorizar los editores, a grandes rasgos, en dos tipos visuales y funcionales. En los primeros, están los editores que solo hacen realce de sintaxis y plegado de bloques (ej. colapsar las líneas entre dos corchetes). Los segundos manejan referencias cruzadas y puede hacer cambios estructurales (cambiar nombres, extraer métodos, etc.). Es esta entrada solo me enfoco en los componentes visuales. Esto es:
- Definición del lenguaje (sección 2 del tutorial)
- Análisis gramático y sintáctico (sección 3 del tutorial)
- Definición del analizador léxico y sintáctico (sección 4 del tutorial)
- Realce de sintaxis (sección 5 del tutorial)
- Plegado/colapsado (sección 12 del tutorial)
Más que tan solo repetir lo que dice el tutorial, mi intención es mencionar los pequeños detalles que no son evidentes en el tutorial y ayudarlos a entender como los diferentes aspectos del editor están relacionadas a través de la API (application programming interface – en ingles) de PSI y editores de IntelliJ.
Como ejemplo voy a utilizar los lenguajes de Epsilon, pues mi intención inicial es poder editor programas de Epsilon desde IntelliJ. En la parte 1 de esta serie hablo sobre un solo lenguaje, EOL; en la Parte 2 hablaré de como soportar los demás lenguajes.
El código del editor está en el repositorio de Kinori Tech por si quieres ver el código mientras lees esta entrada.
Definición del Lenguaje
No hay mucho más que agregar sobre esta sección. La única cosa que quiero mencionar es que si estás creando una familia de lenguajes, la clase “Icons” (sección 2.2) puede ser utilizada para todos los lenguajes. Otro aspecto al cual debes poner atención es la creación del icono(s) de los lenguajes. Personalmente encuentro muy útil ver la estructura del proyecto e identificar rápidamente los archivos por tipo. Estas dos páginas tiene la información relevante sobre la creación de iconos para JetBrains:
– https://plugins.jetbrains.com/docs/intellij/work-with-icons-and-images.html
– https://jetbrains.design/intellij/principles/icons/
Gramática y sintaxis
Mi único cambio sugerido es el el Token Type (sección 3.1):
public class EolTokenType extends IElementType {
public EolTokenType(@NotNull @NonNls String debugName) {
super(debugName, EolLanguage.INSTANCE);
}
@Override
public String toString() {
return super.toString(); // vs return "SimpleTokenType." + super.toString();
}
}
Una vez en uso, utilizar “<nombre>TokenType” como prefijo en el método “toString()” hace los mensajes de error difíciles de leer para los usuarios, en efecto el prefijo no da ninguna información útil al usuario final cuando se generan errores de tipo “Se esperaba una COMMA, se encontró LEFT_BRACKET”.
Gramática
Escribir la gramática de un lenguaje (y luego el analizador léxico) son temas que merecen su propia entrada. Sin embargo, si ya has escrito una versión de tu gramática en (E)BNF, traducirla al BNF the IntelliJ toma tiempo pero debe ser relativamente directo. Asegúrate de tener una definición correcta de la gramática antes de continuar.
Análisis léxico y sintáctico
La clase que necesita más atención es la “Parser Definiton” (análisis sintáctico). Para mí, los métodos clave son getWhitespaceTokens, getCommentTokens y getStringLiteralElements. Estos tres métodos le dicen al editor que símbolos deben ser considerados como espacio (usualmente espacios y fin de línea), comentarios y cadenas de letras. Asegúrate de retornar todos los tipos de símbolos, ej. comentarios de una o de múltiples líneas.
Análisis Léxico
En el pasado he utilizado Antlr y XText para diseñar lenguajes, así que tener que definir el análisis léxico por separado fue una experiencia nueva. Creo que la documentación de JFlex es un poco difícil de entender, y no puede encontrar buenos tutoriales en la red. De nuevo, es un tema que merece su propia entrada. Solo ten presente que los “estados léxicos” son muy útiles en JFlex. Paciencia, yo solo logré ajustar mi análisis léxico luego de muchas pruebas y errores.
Realce de Sintaxis
En este punto, el análisis léxico debe estar creando símbolos (tokens en ingles) y el análisis sintáctico los debe estar usando para validar la gramática de un programa. Si estas usando la vista PSI (como recomienda el tutorial), debes ver como se construye el CST (árbol de sintaxis concreta – concrete syntax tree) y los errores se deben estar reportando.
¡Ahora viene la magia!
Primero debemos agrupar los símbolos en “grupos de realce”. Usualmente se utilizan diferentes colores para las palabras del lenguaje (ej. for, then, class, etc.), cadenas de caracteres, números, comentarios, etc. Define los grupos que consideres necesarios/útiles y asigna los diferentes símbolos a cada grupo. A cada grupo de realce le podemos asignar un color y un estilo (negritas, itálicas, etc.). Para cada grupo se debe definir un extAttributesKey y un array TextAttributesKey. Creo que se pueden combinar múltiples estilos, pero no he jugado con esa posibilidad (y la documentación al respecto no es muy buena).
El tutorial sugiere el uso de campos estáticos para los grupos:
public static final TextAttributesKey EOL_OPERATORS =
createTextAttributesKey("EOL_OPERATORS", DefaultLanguageHighlighterColors.OPERATION_SIGN);
...
public static final TextAttributesKey[] EOL_OPERATOR_KEYS = new TextAttributesKey[]{EOL_OPERATORS};
Adicionalmente, usan la clase “DefaultLanguageHighlighterColors” que define un set predeterminado de estilos. Los estilos predeterminados son los utilizados por IntelliJ así que son un buen punto de inicio. Para estilos diferentes se debe crear “TextAttributesKey” propias a partir de objetos TextAttributes. El API favorece el reuso, al menos para que las definiciones sean estáticas. Sin embargo, se pueden crear de manera no estática en el constructor de nuestro “Highlighter”. La clase TextAttributes es su amiga.
Para EOL, definí 8 grupos:
- operadores: aritméticos (+, -, /, etc.) y específicos de EOL (!, |, ::=, etc.).
- operadores de texto: operadores lógicos (and, or, etc.)
- palabras clave: for, if, class, operation, etc.
- anotaciones @cached, @lazy, etc.
- numeros
- funciones del lenguage: select, collect, includes, etc.
- cadena de caracteres
- comentarios
Los símbolos que perteneces a cada grupo son definidos en el método getTokenHighlights. Seguí la idea del tutorial con multiples “or”s, pero una optimización puede ser definirlos como sets.
package org.eclipse.epislon.labs.intellij.grammar.editor.eol;
import com.intellij.lexer.Lexer;
import com.intellij.openapi.editor.DefaultLanguageHighlighterColors;
import com.intellij.openapi.editor.HighlighterColors;
import com.intellij.openapi.editor.colors.TextAttributesKey;
import com.intellij.openapi.fileTypes.SyntaxHighlighterBase;
import com.intellij.psi.TokenType;
import com.intellij.psi.tree.IElementType;
import org.eclipse.epislon.labs.intellij.grammar.parser.eol.EolLexerAdapter;
import org.eclipse.epislon.labs.intellij.grammar.psi.eol.EolTypes;
import org.jetbrains.annotations.NotNull;
import static com.intellij.openapi.editor.colors.TextAttributesKey.createTextAttributesKey;
public class EolSyntaxHighlighter extends SyntaxHighlighterBase {
public static final TextAttributesKey EOL_OPERATORS =
createTextAttributesKey("EOL_OPERATORS", DefaultLanguageHighlighterColors.OPERATION_SIGN);
public static final TextAttributesKey EOL_TEXT_OPERATORS =
createTextAttributesKey("EOL_TEXT_OPERATORS", DefaultLanguageHighlighterColors.LOCAL_VARIABLE);
public static final TextAttributesKey EOL_KEYWORD =
createTextAttributesKey("EOL_KEYWORD", DefaultLanguageHighlighterColors.INSTANCE_METHOD);
public static final TextAttributesKey EOL_ANNOTATIONS =
createTextAttributesKey("EOL_ANNOTATIONS", DefaultLanguageHighlighterColors.METADATA);
public static final TextAttributesKey EOL_NUMBERS =
createTextAttributesKey("EOL_NUMBERS", DefaultLanguageHighlighterColors.NUMBER);
public static final TextAttributesKey EOL_BUILTIN =
createTextAttributesKey("EOL_BUILTIN", DefaultLanguageHighlighterColors.FUNCTION_CALL);
public static final TextAttributesKey EOL_STRING =
createTextAttributesKey("STRING", DefaultLanguageHighlighterColors.STRING);
public static final TextAttributesKey EOL_COMMENT =
createTextAttributesKey("SIMPLE_COMMENT", DefaultLanguageHighlighterColors.LINE_COMMENT);
public static final TextAttributesKey BAD_CHARACTER =
createTextAttributesKey("SIMPLE_BAD_CHARACTER", HighlighterColors.BAD_CHARACTER);
public static final TextAttributesKey[] EOL_OPERATOR_KEYS = new TextAttributesKey[]{EOL_OPERATORS};
public static final TextAttributesKey[] EOL_TEXT_OPERATOR_KEYS = new TextAttributesKey[]{EOL_TEXT_OPERATORS};
public static final TextAttributesKey[] EOL_KEYWORD_KEYS = new TextAttributesKey[]{EOL_KEYWORD};
public static final TextAttributesKey[] EOL_ANNOTATIONS_KEYS = new TextAttributesKey[]{EOL_ANNOTATIONS};
public static final TextAttributesKey[] EOL_NUMBER_KEYS = new TextAttributesKey[]{EOL_NUMBERS};
public static final TextAttributesKey[] EOL_BUILTIN_KEYS = new TextAttributesKey[]{EOL_BUILTIN};
public static final TextAttributesKey[] EOL_STRING_KEYS = new TextAttributesKey[]{EOL_STRING};
public static final TextAttributesKey[] EOL_COMMENT_KEYS = new TextAttributesKey[]{EOL_COMMENT};
public static final TextAttributesKey[] EMPTY_KEYS = new TextAttributesKey[0];
private static final TextAttributesKey[] BAD_CHAR_KEYS = new TextAttributesKey[]{BAD_CHARACTER};
@NotNull
@Override
public Lexer getHighlightingLexer() {
return new EolLexerAdapter();
}
@NotNull
@Override
public TextAttributesKey[] getTokenHighlights(IElementType tokenType) {
if (tokenType.equals(EolTypes.EOL_ARROW_OP)
|| tokenType.equals(EolTypes.EOL_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_COLON_OP)
|| tokenType.equals(EolTypes.EOL_DIV_ASSIG_OP)
|| tokenType.equals(EolTypes.EOL_DIV_OP)
|| tokenType.equals(EolTypes.EOL_ENUM_OP)
|| tokenType.equals(EolTypes.EOL_EQ_OP)
|| tokenType.equals(EolTypes.EOL_EQUIV_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_GE_OP)
|| tokenType.equals(EolTypes.EOL_GT_OP)
|| tokenType.equals(EolTypes.EOL_IMPLIES_OP)
|| tokenType.equals(EolTypes.EOL_IN_OP)
|| tokenType.equals(EolTypes.EOL_INC_OP)
|| tokenType.equals(EolTypes.EOL_LE_OP)
|| tokenType.equals(EolTypes.EOL_LT_OP)
|| tokenType.equals(EolTypes.EOL_MINUS_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_MODEL_OP)
|| tokenType.equals(EolTypes.EOL_NE_OP)
|| tokenType.equals(EolTypes.EOL_NEG_OP)
|| tokenType.equals(EolTypes.EOL_PLUS_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_PLUS_OP)
|| tokenType.equals(EolTypes.EOL_POINT_OP)
|| tokenType.equals(EolTypes.EOL_POINT_POINT_OP)
|| tokenType.equals(EolTypes.EOL_QUAL_OP)
|| tokenType.equals(EolTypes.EOL_SPECIAL_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_THEN_OP)
|| tokenType.equals(EolTypes.EOL_TIMES_ASSIGN_OP)
|| tokenType.equals(EolTypes.EOL_TIMES_OP)
) {
return EOL_OPERATOR_KEYS;
}
else if(tokenType.equals(EolTypes.EOL_AND_OP)
|| tokenType.equals(EolTypes.EOL_NOT_OP)
|| tokenType.equals(EolTypes.EOL_OR_OP)
|| tokenType.equals(EolTypes.EOL_XOR_OP)
) {
return EOL_TEXT_OPERATOR_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_ABORT_KEY)
|| tokenType.equals(EolTypes.EOL_BAG_KEY)
|| tokenType.equals(EolTypes.EOL_BREAK_ALL_KEY)
|| tokenType.equals(EolTypes.EOL_BREAK_KEY)
|| tokenType.equals(EolTypes.EOL_CASE_KEY)
|| tokenType.equals(EolTypes.EOL_COL_KEY)
|| tokenType.equals(EolTypes.EOL_CONTINUE_KEY)
|| tokenType.equals(EolTypes.EOL_DEFAULT_KEY)
|| tokenType.equals(EolTypes.EOL_DELETE_KEY)
|| tokenType.equals(EolTypes.EOL_ELSE_KEY)
|| tokenType.equals(EolTypes.EOL_EXT_KEY)
|| tokenType.equals(EolTypes.EOL_FALSE_KEY)
|| tokenType.equals(EolTypes.EOL_FOR_KEY)
|| tokenType.equals(EolTypes.EOL_FUNCTION_KEY)
|| tokenType.equals(EolTypes.EOL_IF_KEY)
|| tokenType.equals(EolTypes.EOL_IMPORT_KEY)
|| tokenType.equals(EolTypes.EOL_IN_KEY)
|| tokenType.equals(EolTypes.EOL_LIST_KEY)
|| tokenType.equals(EolTypes.EOL_MAP_KEY)
|| tokenType.equals(EolTypes.EOL_NATIVE_KEY)
|| tokenType.equals(EolTypes.EOL_NEW_KEY)
|| tokenType.equals(EolTypes.EOL_OPERATION_KEY)
|| tokenType.equals(EolTypes.EOL_ORDSET_KEY)
|| tokenType.equals(EolTypes.EOL_RETURN_KEY)
|| tokenType.equals(EolTypes.EOL_SEQ_KEY)
|| tokenType.equals(EolTypes.EOL_SET_KEY)
|| tokenType.equals(EolTypes.EOL_SWITCH_KEY)
|| tokenType.equals(EolTypes.EOL_THROW_KEY)
|| tokenType.equals(EolTypes.EOL_TRANS_KEY)
|| tokenType.equals(EolTypes.EOL_TRUE_KEY)
|| tokenType.equals(EolTypes.EOL_VAR_KEY)
|| tokenType.equals(EolTypes.EOL_WHILE_KEY)
) {
return EOL_KEYWORD_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_ANNOTATION)
|| tokenType.equals(EolTypes.EOL_EXEC_ANNOT)
|| tokenType.equals(EolTypes.EOL_EXECUTABLE_ANNOTATION)) {
return EOL_ANNOTATIONS_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_FLOAT)) {
return EOL_NUMBER_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_SELF_BIN)
|| tokenType.equals(EolTypes.EOL_LOOP_CNT_BIN)
|| tokenType.equals(EolTypes.EOL_HAS_MORE_BIN)) {
return EOL_BUILTIN_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_STRING)) {
return EOL_STRING_KEYS;
}
else if (tokenType.equals(EolTypes.EOL_BLOCK_COMMENT) || tokenType.equals(EolTypes.EOL_LINE_COMMENT)) {
return EOL_COMMENT_KEYS;
}
else if (tokenType.equals(TokenType.BAD_CHARACTER)) {
return BAD_CHAR_KEYS;
}
else {
return EMPTY_KEYS;
}
}
}
Creador de plegados
Esta fue la parte más difícil de descifrar. El método buildFoldRegions (construir regiones de plegado) en la clase FoldingBuilder es la clave; en resumen es necesario construir las regiones de plagado para los elementos PSI que se requiera (usualmente bloques de código, e.g. condicionales y bucles). Cabe notar que la creación de plegados utiliza la API de PSI, es decir que tenemos que trabajar con los constructos de nuestro lenguaje, no con tokens. El método buildFoldRegions recibe el parámetro quick. Debido a que la construcción de plegados puede tomar mucho tiempo, el parámetro quick (rápido) se debe utilizar para construir un subset de los plegados que se pueda hacer rápidamente.
Para EOL, escogimos dos constructos para plegar, inspirados por lo que se hace en Java: imports y code blocks (todos los bloques entre corchetes). Si el parámetro quick es verdadero, solo construimos los plegados para imports.
// imports
EpsilonModule module = PsiTreeUtil.findChildOfAnyType(root, false, EpsilonModule.class);
if ((module != null) && !module.getImportStatementList().isEmpty()) {
descriptors.add(new ImportStatementBlockFolding(
module.getNode(),
new TextRange(
module.getImportStatementList().get(0).getTextRange().getStartOffset() + 7,
module.getImportStatementList().get(module.getImportStatementList().size()-1).getTextRange().getEndOffset() + 1))
);
}
La parte más difícil de ajustar son los parámetros para los TextRange. Para los imports, queremos que cuando el plegado está cerrado, se vea la palabra import seguido de puntos suspensivos. Como la palabra “import” tiene 7 letras, el text rage empieza en el inicio del offset + 7. El fin del plegado es es último punto y coma (“;”) + 1, para que no se vea el “;”. Para los bloques, recordemos que están definidos por:
...
// Statements
statementBlock ::= '{' statement* '}'
...
En este caso no queremos cambiar el TextRange ya que quermos que se vean los corchetes que están plegados. Por último, el método getPlaceholderText nos permite cambiar el texto que se muestra en los pliegues. En nuestro caso retornamos puntos suspensivos.
package org.eclipse.epislon.labs.intellij.grammar.language.eol;
import com.intellij.lang.ASTNode;
import com.intellij.lang.folding.*;
import com.intellij.openapi.editor.*;
import com.intellij.openapi.util.TextRange;
import com.intellij.psi.*;
import com.intellij.psi.util.PsiTreeUtil;
import org.eclipse.epislon.labs.intellij.grammar.psi.EpsilonModule;
import org.eclipse.epislon.labs.intellij.grammar.psi.eol.*;
import org.jetbrains.annotations.*;
import java.util.*;
public class EolFoldingBuilder extends FoldingBuilderEx {
public class EolStatementBlockFolding extends FoldingDescriptor {
public EolStatementBlockFolding(@NotNull ASTNode node, @NotNull TextRange range) {
super(node, range);
}
@Nullable
@Override
public String getPlaceholderText() {
return "...";
}
}
public class ImportStatementBlockFolding extends FoldingDescriptor {
public ImportStatementBlockFolding(@NotNull ASTNode node, @NotNull TextRange range) {
super(node, range);
}
@Nullable
@Override
public String getPlaceholderText() {
return "...";
}
}
@NotNull
@Override
public FoldingDescriptor[] buildFoldRegions(@NotNull PsiElement root, @NotNull Document document, boolean quick) {
List<FoldingDescriptor> descriptors = new ArrayList<>();
// imports
EpsilonModule module = PsiTreeUtil.findChildOfAnyType(root, false, EpsilonModule.class);
if ((module != null) && !module.getImportStatementList().isEmpty()) {
descriptors.add(new ImportStatementBlockFolding(
module.getNode(),
new TextRange(module.getImportStatementList().get(0).getTextRange().getStartOffset() + 7,
module.getImportStatementList().get(module.getImportStatementList().size()-1).getTextRange().getEndOffset() + 1))
);
}
if (!quick) {
// all StatementBlocks are collapsible, and since most expressions with a block use a StatementBlock we cover
// most required foldings
for (final EolStatementBlock stmt : PsiTreeUtil.findChildrenOfAnyType(root, false, EolStatementBlock.class)) {
createBlockFoldingDescriptor(descriptors, stmt, stmt.getNode());
}
}
return descriptors.toArray(new FoldingDescriptor[descriptors.size()]);
}
@Nullable
@Override
public String getPlaceholderText(@NotNull ASTNode node) {
return "...";
}
// Only calls for nodes that have a FoldingDescriptor
@Override
public boolean isCollapsedByDefault(@NotNull ASTNode node) {
if (node.getElementType().equals(EolTypes.EOL_MODULE)) {
return true;
}
return false;
}
protected void createBlockFoldingDescriptor(
List<FoldingDescriptor> descriptors,
EolStatementBlock statementBlock,
ASTNode node) {
if (statementBlock != null) {
descriptors.add(new EolStatementBlockFolding(
node,
new TextRange(
statementBlock.getTextRange().getStartOffset() + 1,
statementBlock.getTextRange().getEndOffset() - 1)));
}
}
}
El resutlado
A continuación hay una captura de pantalla con el editor de EOL abierto en el fondo y las opciones de realce de sintaxis en el frente.
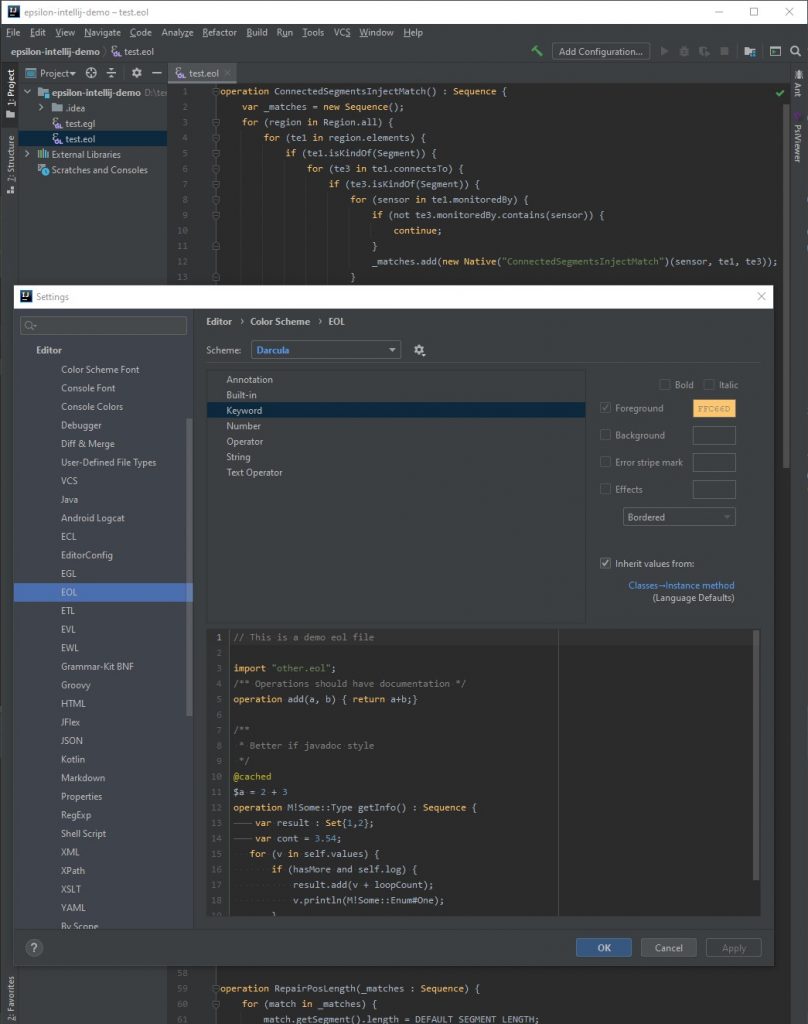
Los editores se pueden instalar acá.